
mybatis 动态SQL
mybatis 动态SQL
ruoxijun注解,多表查询与动态SQL,缓存
使用注解开发:
使用注解进行开发时要注意:注解来映射简单语句会使代码显得更加简洁,但复杂的操作,最好用 XML 来映射语句。
使用注解的方法就不用创建Mapper.xml(可以创建),因此在mybatis-config.xml配置文件中注册映射器时建议使用mapper的class属性利用Mapper接口来注册映射器:
1 | <mappers> |
1. 利用注解查表(@Select):
在Mapper接口中定义查询方法,并在方法上使用 @Select注解,参数为SQL查询语句字符串:
1 |
|
使用按正常步骤调用方法即可。
存在多个参数时使用注解方式就能不再利用对象传参了,在参数(参数必须为基本类型)前使用@Param注解并给参数取别名,在SQL语句中直接**#{别名}**方式调用参数即可:
1 |
|
此方法定义的参数也可在Mapper.xml中直接使用,并且不用parameterType属性声明类型:
1 | <select id="findUserList" resultType="userPojo"> |
2. 增(Insert@):
1 |
|
3. 改(Update@):
1 |
|
4. 删(Delete@):
1 |
|
Mybatis 执行流程解析:
- 获取加载resources中的全局配置文件流(mybatis-config.xml)。
- 实例化SqlSessionFactoryBuilder调用build方法通过配置文件流解析配置文件(底层使用XMLConfigBuilder对象解析xml文件)。利用Configuration对象存储所有配置信息。
- SqlSessionFactory实例化。
- transactional事务管理器。
- 创建executor执行器。
- 创建SqlSession。
- 实现CRUD(SQL增删改查操作),若事务出现问题事务回滚到第4步。
- 查看CRUD是否执行成功,失败则回滚到第4步。
- 提交事务并关闭SqlSession。
之前我们说过MyBatis对数据库的增删改操作
SqlSession必须手动提交事务(commit)才能表修改成功。Mybatis中也提供了指定提交事务的方法:
sqlSessionFactory.openSession(true)即在创建
SqlSession时在openSession方法中传入true参数则此SqlSession执行的增删改方法都会自动提交事务。
Lombok 使用:
idea在settings的插件中搜索 lombok 下载。为了使用提示功能。
导入lombok的依赖:
1
2
3
4
5
6
7<!-- https://mvnrepository.com/artifact/org.projectlombok/lombok -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.12</version>
<scope>provided</scope><!-- 建议去掉 -->
</dependency>注解与使用:
- @Data:在 类 上,提供类所有属性的 get 和 set 方法,还提供了equals、canEqual、hashCode、toString 方法。
- @Setter:在 属性 上,为单个属性提供 set 方法。在 类 上,为该类所有的属性提供 set 方法, 都提供默认构造方法。
- @Getter:与 @Setter 类似。
- @Log4j:在 类 上,为类提供一个 属性名为 log 的 log4j 日志对象,提供默认构造方法。
- @Slf4j:日志 推荐 使用 @Slf4j ,它与 @Log4j 使用方法类似。
- @AllArgsConstructor:在 类 上,为类提供一个全参的构造方法,将覆盖默认的空参构造。
- @NoArgsConstructor:在 类 上;为类提供一个无参的构造方法。
- @EqualsAndHashCode:在 类 上, 可以生成 equals、canEqual、hashCode 方法。
- @ToString:在 类 上,可以生成所有参数的 toString 方法,还会生成默认的构造方法。
- @Value:在 类 上,生成含所有参数的构造方法,get 方法,还提供equals、hashCode、toString 方法。
多表查询:
现在使用这两个表作为演示:
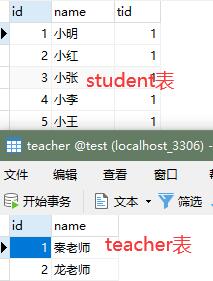
学生表实例类(pojo):
1 | public class Student { // get和set等方法省略...,请自行补齐 |
老师表实例类(pojo):
1 | public class Teacher { // get和set等方法省略...,请自行补齐 |
1. 多对一:
需求:查询所用学生并且查出每个学生对应的老师。
定义Mapper接口与方法:
1 | interface StudentMapper { |
方法一:Mapper.xml中通过 association 的select属性进行子查询:
1 | <!-- 1.查询学生表,并设置结果集 --> |
方法二(建议使用):直接使用SQL多表查询,再配置结果集映射数据:
1 | <!-- 1.书写多表查询SQL语句 --> |
2. 一对多:
需求:查询指定老师并查出该老师的所有学生。
定义Mapper接口与方法:
1 | interface TeacherMapper { |
方法一:Mapper.xml中通过 association 的select属性进行子查询:
1 | <select id="findTeacher" resultMap="teacherMap"> |
方法二(建议使用):直接使用多表查询,再配置结果集映射数据:
1 | <select id="findTeacher" resultMap="teacherMap"> |
3. 多表查询总结:
- 多对一:结果集映射到 对象 使用 association 标签
- 一对多:结果集映射到 集合 使用 collection 标签
- 绑定子查询时 column 属性中的字段值将作为参数传递到子查询中,通过
#{字段名}直接调用 - javatype :指定实体类中成员变量的java类型
- ofType :当成员变量为集合时指定其元素的java类型(泛型的类型)
- 多对一(association),一对多(collection)可无限嵌套
动态sql:
Mybatis动态SQL官方API:https://mybatis.org/mybatis-3/zh/dynamic-sql.html
Mybatis动态SQL标签与JSTL(jsp)类似,你对动态 SQL 元素可能会感觉似曾相识。
1. if:
传入的参数:
1 | Map<String,Object> map = new HashMap<>(); |
if标签中test属性值就是条件,当条件成立时标签内的内容才会显现。并且你可以发现在test属性值内访问参数不需要再通过 #{} 就可以直接访问:
1 | <select id="findStudents" resultType="student" parameterType="map"> |
2. choose、when、otherwise:
choose与java中的switch类似,一旦一个when满足test条件其它的就不会再判断其它when。otherwise只有当所有的when都不满足时调用。when和otherwise中可嵌套if,if中可嵌套choose。
1 | <select id="findStudents" resultType="student" parameterType="map"> |
3. trim、where、set:
- where:where 标签在SQL语句中只在需要使用where的位置使用,并只会在子元素返回内容的情况下才插入 where关键字 。而且若子句的开头为 “AND” 或 “OR”,where 元素会将它们自动去除。
1 | <select id="findStudents" resultType="student" parameterType="map"> |
- set:set 标签在SQL语句中只在需要使用set的位置使用,set 元素会动态地在行首插入 SET 关键字,并会自动删掉额外的逗号。
1 | <update id="updateStudent" parameterType="map"> |
运行后SQL语句为 update student SET name=?, tid=? WHERE id=? 可以看到 tid=#{tid}, 后的,逗号被去除。还有 and id=#{id} 判断开头的 and 也自动去除。
- trim:请到官网了解,它就是定义去除关键字的标签。
1 | <trim prefix="WHERE" prefixOverrides="AND |OR "> |
4. foreach:
- 首先我们了解一下SQL片段:
1 | <!-- sql标签:定义SQL片段 |
- foreach的使用:
Mapper接口中定义方法:
1 | // 使用Param注解取别名方便在SQL中调用,也可Map传参put一个List |
Mapper.xml中使用foreach动态编写SQL语句:
1 | <!-- collection:可遍历的集合 |
使用后拼接为:select * from student where id in ( ? , ? ,...)
Mybatis 缓存:
Mybatis 缓存官方文档:https://mybatis.org/mybatis-3/zh/sqlmap-xml.html#cache
1.缓存简介:
缓存就是将用户经常查询并且不经常改变的数据放在缓存中,就不用多次从数据库中去查询重复的数据。Mybatis中默认定义了两级缓存。一级缓存默认开启,二级缓存需用手动开启。
2.一级缓存:
- 一级缓存是默认开启的,也无法关闭。一个SqlSession就是一个一级缓存,一级缓存的作用域是一个SqlSession创建到关闭内。
- 同一个SqlSession查询同样的数据,只有第一次会从数据库查询。之后都是从缓存中获取,除非SqlSession执行清空缓存
clearCache或者执行insert、update 和 delete 语句都会刷新缓存。
实例1:
1 | SqlSession sqlSession1 = GetSqlSession.getSqlSession(); |
部分日志:
1 | ==> Preparing: select * from student // 第一次执行数据库查询 |
实例2:
1 | SqlSession sqlSession1 = GetSqlSession.getSqlSession(); |
部分日志:
1 | ==> Preparing: select * from student |
实例3::
1 | SqlSession sqlSession1 = GetSqlSession.getSqlSession(); |
部分日志:
1 | ==> Preparing: select * from student |
3.二级缓存:
要启用全局的二级缓存,只需要在你的 SQL 映射文件(Mapper.xml)中添加一行:
1 | <cache/> |
- 二级缓存作用域是一个Mapper.xml。也就是说只要
getMapper(Mapper.class)对应同一个文件Mapper.xml,那么它们就是同一个二级缓存。 - 工作机制:一个SqlSession查询一条数据,查询完成后首先会放在一级缓存中。当一级缓存(SqlSession)被关闭时一级缓存中的数据会被转存到二级缓存中。
- 查询机制:查询数据时首先会到 二级缓存 再查询 一级缓存 最后还是没有则从数据库查询。
4.自定义缓存:
请了解数据库底层后再查看官网。


